
Serverless Clean Architecture & Code with Domain-Driven Design 🚀
Using clean code and architectures in our Serverless solutions to ensure clean separation of code and infrastructure; with examples written in the AWS CDK and TypeScript.

Contents
✔️ Introduction
✔️ What is Clean Architecture and why do we need it?
✔️ The Serverless Approach
✔️ Key pieces of the puzzle
✔️ Why use this approach?
✔️ Wrapping up
Part 2 of the article can be found here:
👇 Before we go any further — please connect with me on LinkedIn for future blog posts and Serverless news https://www.linkedin.com/in/lee-james-gilmore/

Introduction
In this article we are going to create an app for our fictitious company ‘Onion Sounds — Lee James Online Sound Studio’, allowing us to demonstrate one way to structure your Serverless solutions often called ‘clean’, ‘hexagonal’ or ‘onion’ architectures; which is based on experience in the Serverless and TypeScript World with functional programming and domain-driven design i.e. DDD.
We will also discuss the advantages and reasons for this architectural approach throughout the article.

We are going to build the following small application using TypeScript and the CDK to talk through the approach:

The flow through the diagram is as follows:
- Customers can interact with our API using Amazon API Gateway.
- The customer can create an account through the API which invokes our
CreateAccountAWS Lambda function. - The customer account is created and stored in Amazon DynamoDB as our data store.
- Customers can also retrieve their account details through the same API and data store.
- Customers can upgrade their subscriptions to access more songs through the API.
- A ‘
CustomerAccountUpgraded’ event is published on success of upgrading the account to Amazon EventBridge. (The same with Customer Account created — removed from the diagram for brevity)
You can find the code repo for this article here:
Why did I write this article?
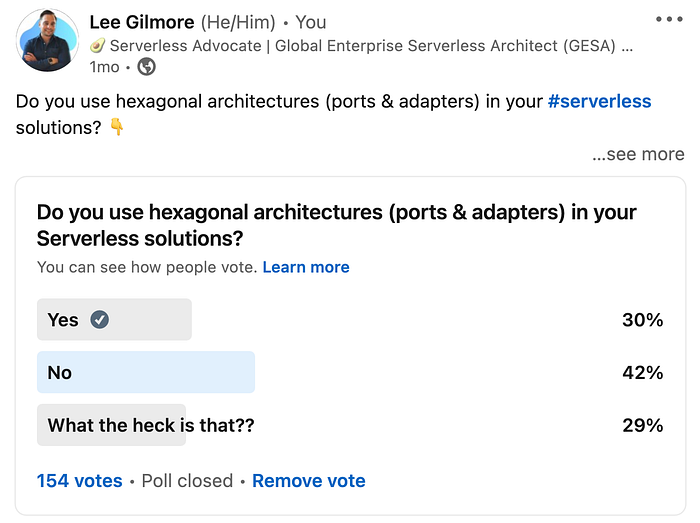
I wrote this article based on a LinkedIn poll I did a few weeks back, where only 30% of people that voted currently use a similar approach (onion/hexagonal/clean), and almost the same again (29%) not even knowing what they were. I also see in many organisations poor abstraction of code which leads to many issues at scale (further detailed below):
What is a Clean Architecture and why do we need it?
OK, so let’s first start by going through what the similarities are with Clean, Hexagonal and Onion architectures, and why we need these approaches in modern day Serverless enterprises.
Each of these different approaches we will discuss focus on being:
✔️ Independent of Frameworks. The architecture does not depend on the existence of some library of feature laden software. This allows you to use such frameworks as tools, rather than having to cram your system into their limited constraints.
✔️ Testable. The business rules can be tested without the UI, Database, Web Server, or any other external element.
✔️ Independent of UI. The UI can change easily, without changing the rest of the system. A Web UI could be replaced with a console UI, for example, without changing the business rules.
✔️ Independent of Database. You can swap out Oracle or SQL Server, for Mongo, BigTable, CouchDB, or something else. Your business rules are not bound to the database.
✔️ Independent of any external agency. In fact your business rules simply don’t know anything at all about the outside world.
Let’s cover each of these approaches independently now at a high level below.
Hexagonal Architecture
Hexagonal Architecture is described by Wikipedia as:
“The hexagonal architecture, or ports and adapters architecture, is an architectural pattern used in software design. It aims at creating loosely coupled application components that can be easily connected to their software environment by means of ports and adapters. This makes components exchangeable at any level and facilitates test automation” — https://en.wikipedia.org/wiki/Hexagonal_architecture_(software)
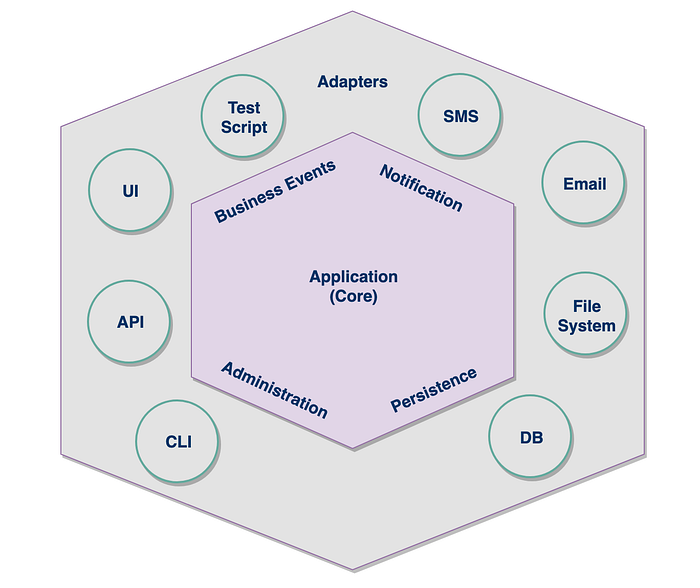
This was first coined by Alistair Cockburn in 2005. Many people like to call this ‘Ports & Adapters’ over ‘Hexagonal Architectures’, as there isn’t necessarily six sides to this approach; but was just used to show multiple adapters and the differentiation between the two sides.
The key premise of this pattern is to ensure there is a key abstraction between our core business domain which is technology agnostic, and the interactions with technology (databases, UI, APIs etc), all through the use of adapters.
Onion Architectures
Jeffery Palermo in 2008 came up with the architectural pattern of ‘Onion Architectures’ in the following article.
“The onion architecture proposed by Jeffrey Palermo in 2008 is similar to the hexagonal architecture: it also externalises the infrastructure with interfaces to ensure loose coupling between the application and the database. It decomposes further the application core into several concentric rings using inversion of control.” — Wikipedia

The fundamental rule is that all code can depend on layers more central, but code cannot depend on layers further out from the core. In other words, all coupling is toward the centre. This architecture is unashamedly biased toward object-oriented programming, and it puts objects before all others.
Clean Architectures
Last but not least, Robert “Uncle Bob” Martin discussed Clean Architectures in 2012 within the following post.
“The clean architecture proposed by Robert C. Martin in 2012 combines the principles of the hexagonal architecture, the onion architecture and several other variants; It provides additional levels of detail of the component, which are presented as concentric rings. It isolates adapters and interfaces (user interface, databases, external systems, devices) in the outer rings of the architecture and leaves the inner rings for use cases and entities. The clean architecture uses the principle of dependency inversion with the strict rule that dependencies shall only exist between an outer ring to an inner ring and never the contrary.” — Wikipedia

It very much builds as a pattern on top of the other approaches, changing ‘Application Services’ to ‘Use Cases’, and ‘Domain Model’ is replaced with ‘Entities’ which make up the Enterprise wide business rules.
The notion of ‘Screaming Architectures’ is also introduced which I am a huge fan of, with the premise being that it should be extremely obvious what an application or microservice does at a quick glance.
The Serverless Approach ✔️
The following diagram shows my approach in the Serverless and TypeScript World which we will discuss in detail as we go through, and tie this back into our example and code repo as we go. This is very much based on the previous approaches above, but for the Serverless and TypeScript World:

Firstly, what is typical of organisations that don’t use these approaches?
So before we go into discussing the diagram above and why we need it in the Serverless World, lets look at what I typically see in enterprise organisations as a comparison:
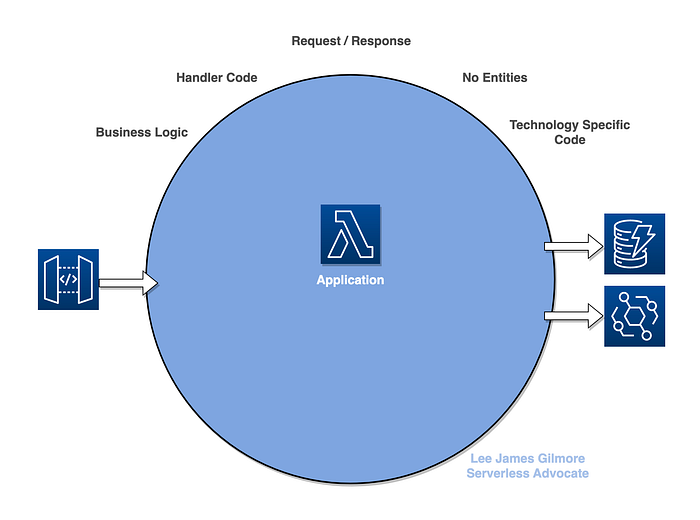
We can see that in the diagram above we don’t have any separation at all around our code and infrastructure, and our individual Lambda functions become dumping grounds for business logic, handler code, request and response mapping and more.. lets see this below as actual code:
As we can see from this pretty typical example (comments in the code above), we have four types of code in one file:
❌ Lambda function handler code.
❌ AWS external services code.
❌ Domain logic for creating and validating an order.
❌ Environment variables scattered through files.
We find based on the typical example above that we:
❌ Struggle to test the code as we are mocking so many services.
❌ The code is very brittle and hard to maintain.
❌ We have a lot of code duplication across many functions.
❌ Domain logic is leaking across many functions.
❌ And we would struggle to move this application to containers or equivalent without a full rewrite.
“That is just one function..now go multiply this with your hundreds/thousands of functions within your organisation.. Ouch!”
If we then extrapolate this out across an organisation, we can see that our business logic then becomes dispersed and diluted across a myriad of functions (the domain logic being the green circles within each lambda):
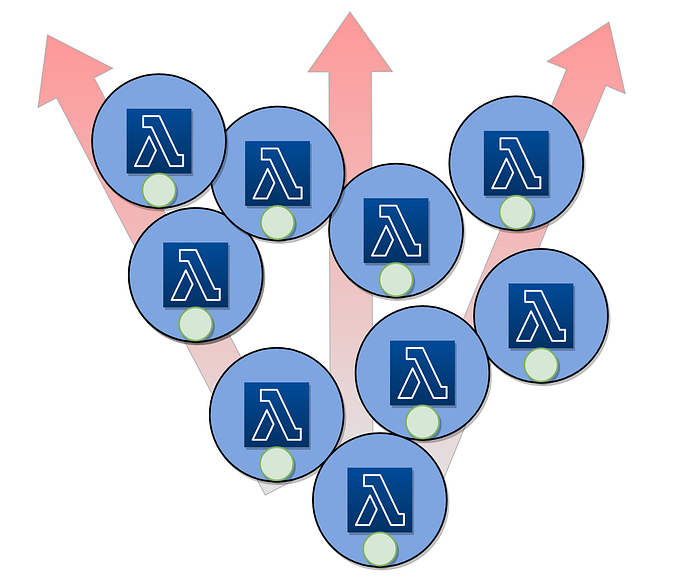
If you then take the stance that you may have hundreds or even thousands of these functions, then you have a problem! Where is your domain logic in your organisation??
“Where is your domain logic in your organisation??”
Let’s cover off some of the key pieces of the puzzle in the next section.
Key pieces of the puzzle
Now let’s talk through the main pieces of the puzzle based on the diagram below, and see how a specific folder structure can support this in our TypeScript solutions:

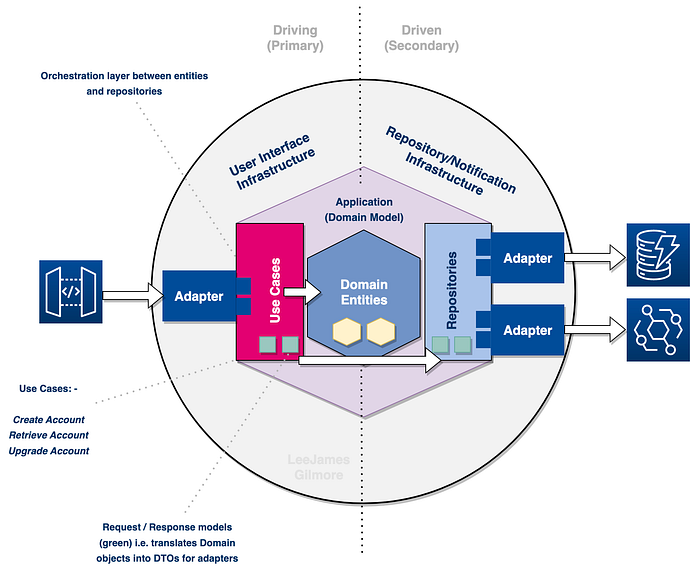
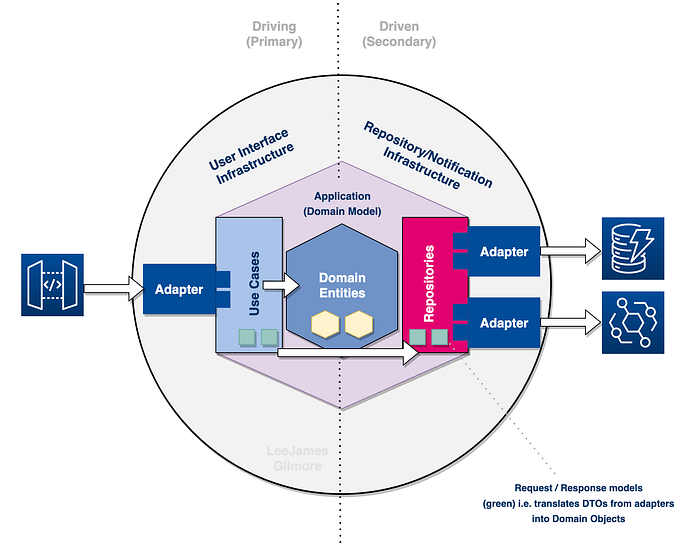
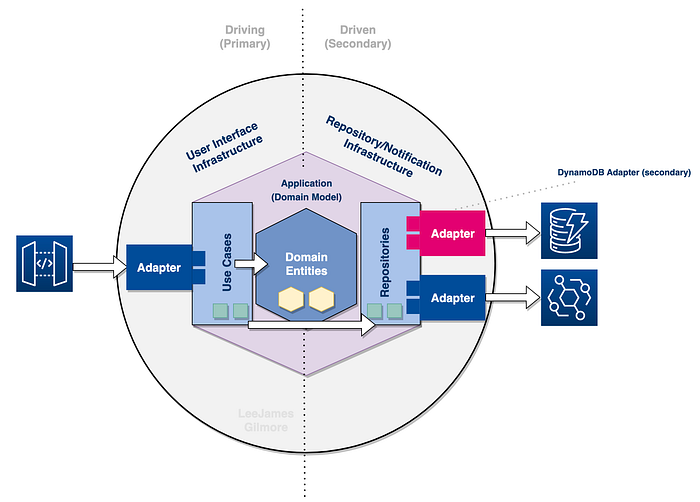
We can see the flow of the service in the diagram which shows:
- A consumer interacts with API Gateway which invokes our Lambda.
- Our
Primary Adaptertakes the input and forwards to ourUse Casewhich is devoid of any technical implications (no notion of Lambda for example in our Use Case) - The
Use Caseis our main business logic flow, for example creating a customer account; which interacts with ourdomain entities(CustomerAccount). - The
Use Casescall theRepositorieswithin their business logic for side effects such as storing the created customer account, and publishing an event off the back of it. - The
repositoriesare technology agnostic and interact withsecondary adaptersto interact with specific technologies. - Our
secondary adaptersin our case are for storing the created accounts in DynamoDB, and publishing the events to Amazon EventBridge. These of course are technology aware.
Domain Model
🌟 Define one rich domain model for each business microservice or Bounded Context.
The Domain Model (Domain Service) is your structured knowledge of the problem within the domain (in our example the Customer Account domain).
The Domain Model should represent the key concepts of the problem domain, and it should identify the relationships among all of the entities within the scope of the domain. The Domain Model is typically a one to one mapping with the bounded context of your microservice.
As we can see from the diagram above, the overall Domain Service includes Use Cases and Repositories also, however not the adapters as they sit on the outside (more on this later).
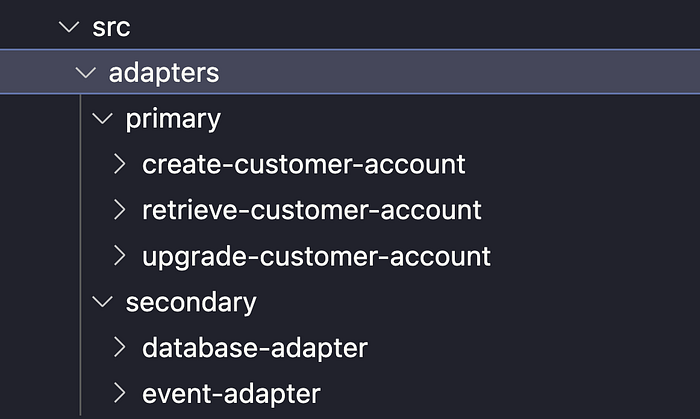
We can see from the screenshot below that we model our Serverless microservice overall application into the following folders which match that of the diagram above, making it easy to reason about as a common approach across many repos:
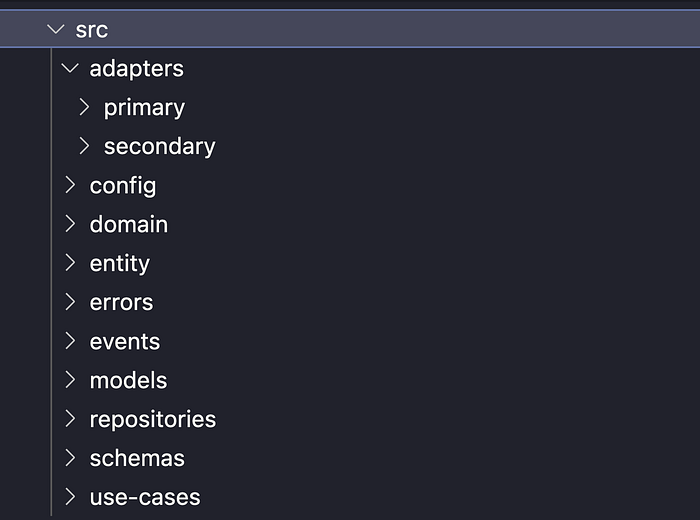
This specific folder structure helps ensure consistency across our domain services and organisation, and ensures that we build our services with the right level of abstraction.
Domain Model summary
✔️ It is a bounded context for our overall domain service.
✔️ It is made up of Domain Entities, Use Cases and Repositories.
Domain Entities
🌟 “An object primarily defined by its identity is called an Entity.” — Eric Evans
Entities are very important in the domain model, since they are the base for a model. Domain entities are the business objects which make up the concepts within our application, for example ‘customer-account’, ‘invoice’ or ‘payment’. These should be the first port of call for any business logic in your domain model/application.
“We never want our objects to end up in an invalid state.”
We need to ensure that we have rich domain entities which have specific business logic which is pertinent to them, rather than anaemic domain entities which are simply POCO classes (getters and setters). This is discussed by Martin Fowler below:

“The catch comes when you look at the behavior, and you realise that there is hardly any behavior on these objects, making them little more than bags of getters and setters.” — Martin Fowler.
We store all of our domain entities in the ‘domain’ folder alongside their tests:
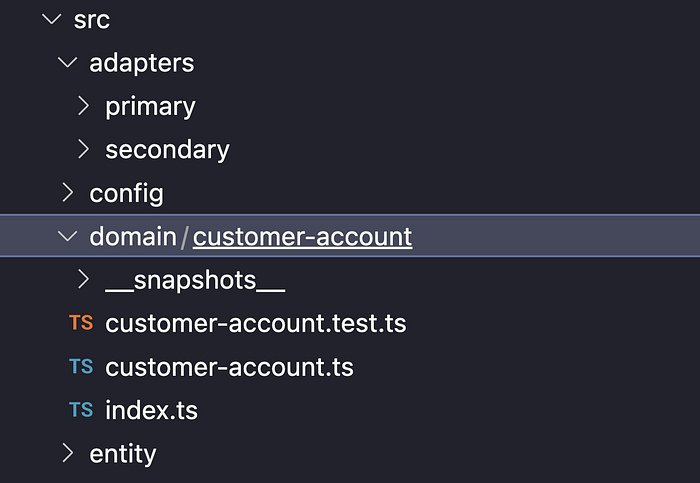
An example in our application could be our Customer Account entity (as shown in the folder structure above), which may have specific business rules that should always apply, such as the following when somebody tries to upgrade the account:
// only allow an upgrade if the payment status is valid
if (instance.props.paymentStatus === PaymentStatus.Invalid) {
throw new ValidationError('Payment is invalid - unable to upgrade');
}We also want to validate the entity when it is created or updated to ensure its integrity at all times, so we would want to be able to validate it at any point in the code with a schema (when pushing to or pulling from a DB for example); using the following:
const instance: CustomerAccount = new CustomerAccount(customerAccountProps);instance.validate(schema);
Persistance Ignorance
One thing that is key when creating our domain model and entities is that we are ignorant of the persistence, which is commonly known as ‘Persistence Ignorance’.
If we look at the code for our ‘Customer Account’ entity we will see no persistence or technology specific code, just pure business logic. All we rely on is the types, errors, schema (to ensure that the entity is always valid), and the abstract base entity:
It’s far more important to model your domain on business behaviour and concepts, and not solely data persistence. DDD simply says that domain modelling comes first and the persistence of the modelled data comes later.
Domain Entity summary
✔️ They are the core of the functionality which makes up our domain.
✔️ These entities have specific domain logic which is pertinent to them.
️✔️ They are technology and framework agnostic.
✔️ They are only accessed via Primary Use Cases.
✔️ They are always in a valid state.
✔️ They are the first port of call for any business logic.
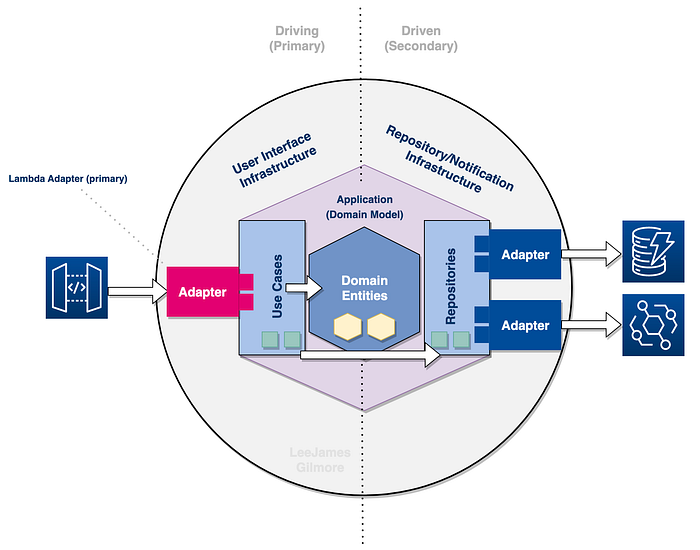
Driving (Primary) vs Driven (Secondary)
When it comes to Hexagonal Architectures we have two key definitions; the Driving side on the left (or primary actors who initiate the interaction), and the Driven side on the right (the secondary actors which perform an action off the back of the initiation).
In our example, the Driving Adapter is the API gateway interaction with Lambda, which takes the user payload and path parameters and passes it to the technology agnostic Use Case.
The Driven actor in our example is the database Adapter which is called via the repository to retrieve or push data to our DynamoDB table. The repository also uses the Adapter for Amazon EventBridge so it can publish events.
Use Cases
🌟 Use cases map user stories to code, are units of work (should live in their own files with their own tests), and are prime candidates for BDD.
Use Cases can interact with one or more entities, and will no doubt contain the business logic for the given use case (over and above the entity specific logic of course). Use cases are shown below from the book ‘Clean Architecture’ and how they are documented:

In our specific example we have ‘create a customer account’, ‘retrieve a customer account’, and ‘upgrade a customer account’. Their names should always start with a verb, and they describe the use cases which make up our overall domain service. Our Use Cases live in the following directory:
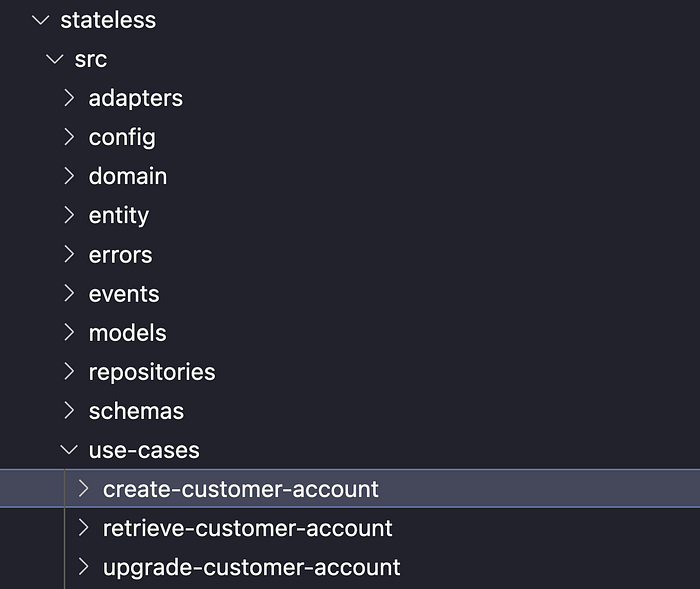
Use Cases also deal with the Request and Response models for the Adapters which consume them (shown in green below).
A Use Case allows any external system or user to interact with our application code via an ‘Adapter’, regardless of what that system is, i.e. technology agnostic.
Use Cases should have no notion of the outside world and how they have been invoked via an adapter (i.e. no notion of specific technologies such as Lambda, API Gateway, DynamoDB etc). Use cases should be pure and deterministic, with any side effects happening in the adapters (in our example the API Gateway adapter).
If we find that we have technical details or implementations in our use cases then we have failed with our adapters!
We can see the code for one of our use cases ‘create customer account’ below:
You can see from the code example above that we are annotating our Use Cases in the same way as Bob C Martin does in his book, which allows us to generate documentation from code using TypeDoc automatically (docs/documentation/index.html). See below:
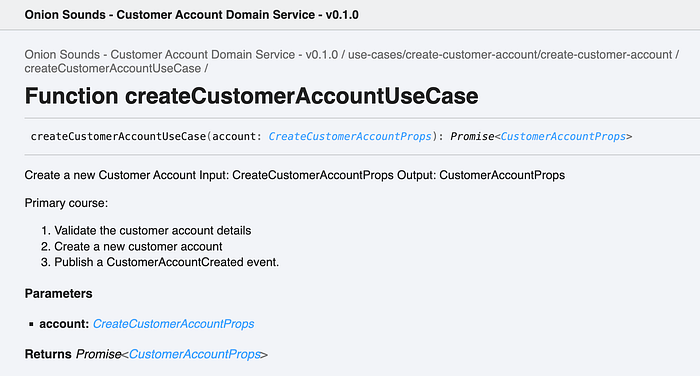
This facilitates our requirement also for ‘Screaming Architectures’ as it is very apparent to any stakeholder the functionality of our Domain Service through its Use Case documentation, or simply by looking at the use cases folder.
Use Case summary
✔️ They are the basis for our functionality which makes up our domain.
✔️ They are technology and framework agnostic.
✔️ They are only interacted with through primary adapters.
✔️ They interact with repositories for side effects (storing of data, raising events etc).
✔️ If we find that we have technical details or implementations in our use cases then we have failed with our adapters.
Repositories
We talked about Use Cases above, but now let’s cover their equivalents on the driven side, repositories.

Repositories are very similar to use cases in as much as they are an abstraction between the domain and the technology (in our case DynamoDB and EventBridge), and they are only ever called via a Use Case or potentially a Domain Entity. This is shown below:
Due to the abstraction of using Repositories in our clean code we can easily swap out one database technology for another by plugging in a different adapter specific to that database technology, without having to change any other code.
Repositories summary
✔️ They never have any business logic, and they are purely the glue code abstraction between the Use Case and the Adapters.
✔️ Allows us to very quickly and easily swap out technologies or frameworks, for example DynamoDB for DocumentDB, just by swapping out the Adapter.
Primary & Secondary Adapters
🌟 “No domain logic is present in an adapter; its only responsibility is a technical transformation between the external world and the domain” — InfoQ.
A Primary Adapter will take the interaction from the technology or framework and interact with the domain code through a Use Case. In this way the Use Case has no notion of who or what is communicating with it, and keeps the architecture and code loosely coupled. We store both our Primary and Secondary adapters in the folder structure below:
In our example our Primary Adapter would specifically be for Lambda, taking in and validating the inputs before calling our Use Case.
“Adapters are the glue between components and the outside world. They tailor the exchanges between the external world and the ports that represent the requirements of the inside of the application component. There can be several adapters for one Use Case, for example, data can be provided by a user through a GUI or a command-line interface, by an automated data source, or by test scripts.”
This means that a Use Case can have many different primary adapters to allow different services to interact with our application. We can see the code below for our primary adapter:
This means we could very easily port some domain functionality from API Gateway and Lambda to EventBridge, SNS or SQS event.
We can now look at the Secondary Adapter which talks to DynamoDB via a repository:
Adapters summary
✔️ They never have any business logic, and they are purely technical for the given actor or consuming service.
✔️ They must confine to the method signature of the Use Case or Repository.
✔️ They allow us to very easily swap out adapters for others which work with different frameworks or technologies.
Dependency Injection and Inversion of Control
One of the key tenants of Hexagonal Architectures and Clean Architectures are Dependency Injection (DI) and IoC (Inversion of Control) using Interfaces; however in the Serverless World with AWS Lambda Functions this seems overkill in my opinion, especially due to some of the limitations with TypeScript (more below).
Why do I say this?
Well, we need to find the sweet spot between abstraction upon abstraction and dependency injection/IoC containers at the root of the application entry point (doing all of the wiring up of interfaces to concrete classes), vs the beauty of Serverless which is its speed and simplicity.
My main concern is ensuring that technology specifics are abstracted away from the domain logic to the outer parts of the applications through abstractions (adapters), and that any adapter can plug into our use cases and repositories as long as they confine to the method signatures. I also want to ensure the adapters which are working with frameworks or technologies have no notion of business rules (no business logic leak!). We need to keep them totally separate, and this approach allows for that.
Inversion of Control/DI specific code
I am also not a fan in TypeScript of having DI package decorators peppered throughout the code itself (I want to keep this clean inline with the approach), such as ‘@injectable’, ‘@injected’ etc, which notoriously only works with class based files as opposed to function based (without lots of horrible workarounds). An example from the InversifyJS framework for class based programming is shown below:
@injectable()
class Katana implements Weapon {
public hit() {
return "cut!";
}
}@injectable()
class Ninja implements Warrior {
private _katana: Weapon;
private _shuriken: ThrowableWeapon;
public constructor(
@inject(TYPES.Weapon) katana: Weapon,
@inject(TYPES.ThrowableWeapon) shuriken: ThrowableWeapon
) {
this._katana = katana;
this._shuriken = shuriken;
}
public fight() { return this._katana.hit(); };
public sneak() { return this._shuriken.throw(); };
}
A Decorator is a special kind of declaration that can be attached to a class declaration, method, accessor, property, or parameter. Decorators use the form
@expression, whereexpressionmust evaluate to a function that will be called at runtime with information about the decorated declaration. — https://www.typescriptlang.org/docs/handbook/decorators.html#decorators
I really don’t want to embed this framework specific code throughout my microservice, even when it does become possible with functions in the future.
TypeScript Functional Programming vs OOP
We also find in the Serverless World with TypeScript that most solutions are built using a functional programming approach over Object Oriented (OOP), and dependency injection frameworks in TypeScript notoriously won’t work well with functions (only classes), due to decorator limitations (see below link).
This approach documented is to ensure from an enterprise perspective we are setting ourselves up in the right way for adaptability and growth with DDD in mind, without pulling in and setting up additional frameworks such as Typed Inject, InversifyJS and others.
Feel free to use the example repo to change the functions to classes and implement inversion of control and DI using Inversify or a similar framework which is very easy to do, if you would like.
Summary
✔️ Decorators for the main DI/IoC frameworks in TypeScript only work with classes and not functions (but is on the future roadmap).
✔️ I don’t want to pepper my clean files with DI specific logic — this goes against everything we are trying to do with keeping a separation between domain and technology.
Why use this approach?
So, as we start to wrap up, what are the benefits of using this approach?
The benefits are widely documented as:
✔️ Prevents domain logic leaking through a service.
✔️ Clear separation between the domain model and the devices/services used for inputs and outputs.
✔️ Prevent technology lock in.
✔️ Allows for non technical use cases which span entities.
✔️ Allows the code to be more easily changed and adapted over time.
✔️ The clear separation allows for easier and more effective testing of our code.
✔️ Allows the domain model to be absent of any technical implementations i.e. focusing purely on the domain and its business logic.
✔️ Conforms to Single Responsibility i.e. SOLID principals.
Wrapping up 👋
Please go and subscribe on my YouTube channel for similar content!

I would love to connect with you also on any of the following:
https://www.linkedin.com/in/lee-james-gilmore/
https://twitter.com/LeeJamesGilmore
If you enjoyed the posts please follow my profile Lee James Gilmore for further posts/series, and don’t forget to connect and say Hi 👋
Please also use the ‘clap’ feature at the bottom of the post if you enjoyed it! (You can clap more than once!!)
About me
“Hi, I’m Lee, an AWS Community Builder, Blogger, AWS certified cloud architect and Enterprise Serverless Architect based in the UK; currently working for City Electrical Factors (UK) & City Electric Supply (US), having worked primarily in full-stack JavaScript on AWS for the past 6 years.
I consider myself a serverless advocate with a love of all things AWS, innovation, software architecture and technology.”
*** The information provided are my own personal views and I accept no responsibility on the use of the information. ***
You may also be interested in the following:
