
Serverless Clean Architecture & Code with Domain-Driven Design — Part 2 🚀
Part 2 of using hexagonal architectures in our Serverless solutions to ensure clean separation of code and infrastructure; with examples written in the AWS CDK and TypeScript.

Contents
✔️ Introduction.
✔️ Aggregates, Value Objects and more..
✔️ Do we really need DDD in Serverless?
✔️ Wrapping up.
The code for the article can be found below:
👇 Before we go any further — please connect with me on LinkedIn for future blog posts and Serverless news https://www.linkedin.com/in/lee-james-gilmore/

Introduction
This article is the second part of ‘Serverless Clean Architecture & Code with Domain-Driven Design 🚀’ below:
In Part 1 we covered the history of Domain-driven Design, the issues we see without using DDD, and how we can apply clean architecture to Serverless to make our solutions clean and adaptive to change (think evolutionary architectures!)

In this part (Part 2) we are going to explicitly cover the following additional key areas of Domain-driven Design (DDD) that we didn’t talk about in Part 1, and we will apply to our code repo:
✔️ Aggregates (and their roots).
✔️ Value Objects.
✔️ Domain Events.
Aggregates, Value Objects and more..
In this section we are going to cover off some of the DDD items that we didn’t cover in Part 1, as we were trying to reduce the cognitive load in covering everything in one go. In Part 3 we will look at Event Sourcing, materialised views (read stores), and CQRS (Command Query Responsibility Segregation).
Aggregates (and their roots)
Let’s start off by defining what an aggregate is:
“Aggregate is a pattern in Domain-Driven Design. A DDD aggregate is a cluster of domain objects that can be treated as a single unit. An example may be an order and its line-items, these will be separate objects, but it’s useful to treat the order (together with its line items) as a single aggregate.
An aggregate will have one of its component objects be the aggregate root. Any references from outside the aggregate should only go to the aggregate root. The root can thus ensure the integrity of the aggregate as a whole.” — https://martinfowler.com/bliki/DDD_Aggregate.html
So, essentially an aggregate is a way of ensuring transactional consistency around a set of related entities and value objects (more on these later), where one of these entities has overall responsibility (as the aggregate ‘root’). This means there is no way to access or modify children entities of this aggregate without going via the top level root entity. This is shown below for our example:
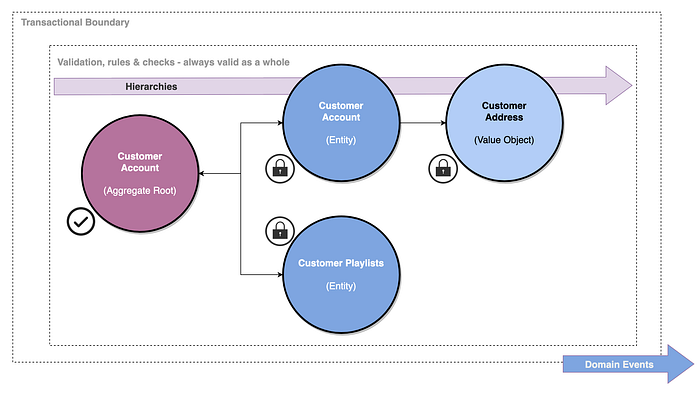
As you can see from our diagram above, in our example we have:
- A top level Customer Account aggregate root which is responsible for ensuring the validity of the cluster of entities at any given point through a transaction boundary, and all access or modification to children entities must go via it.
- We have a Customer Address value object associated to the Customer Account as a 1:1 mapping. This can only be accessed via the root above.
- We have one or more Customer Playlists associated to a Customer Account. This can only be accessed via the root too.
- When there are any significant transactional changes within the aggregate a domain event is created using event carried state transfer.
- Any changes to the entities happen in one transactional boundary to ensure the aggregate is valid at all times as a cohesive group. This is the responsibility of the aggregate root entity.
“An Aggregate is a cluster of associated objects that we treat as a unit for the purpose of data changes. Each Aggregate has a root and a boundary. The boundary defines what is inside the Aggregate. The root is a single, specific Entity contained in the Aggregate. The root is the only member of the Aggregate that outside objects are allowed to hold references to, although objects within the boundary may hold references to each other. Entities other than the root have local identities, but that identity needs to be distinguishable only within the Aggregate because no outside object can ever see it out of the context of the root Entity.” — Eric Evans (Domain Driven Design: Tackling Complexity in the Heart of Software)
A good way of thinking about these clustered objects is typically:
“If I delete the top level entity what other entities should cascade delete?”
This gives you a fairly good indication if they should always change together as a transactional unit. Quite often in systems we see related objects getting out of sync data wise, or orphaned records when an entity is deleted but its children don’t.
We can see looking at our folder structure in the code repository we have some additional folders now for part 2 compared to part 1:

Let’s now have a look what the base aggregate looks like in our example:
We can see that it is a fairly basic abstract class which expects any class which implements this to create a method for retrieving domain events.
We can see the expected shape of the domain events below based off our retrieveDomainEvents() method:
As we are using event-carried state transfer we want to ensure that we have particular properties stored within our domain events so they are useful for other domain services to consume:
✔️ Event source — which domain service raised the event.
✔️ Event name — the unique name of the event.
✔️ Event — the full validated aggregate.
✔️ Event date-time — the date and time the event happened.
✔️ Event version — this is the version of the schema which the event was validated against.
Now let’s look at the Aggregate entity ‘CustomerAccount’ which implements this abstract class in our example:
On lines 45–55 you will see that we create the retrieveDomainEvents method to ensure that we can access the domain events at any given point when we want to publish them.
Note: When we retrieve them we also clear down the array of domain events before returning them to the caller of the
retrieveDomainEventsmethod.
The events are created only when the full aggregate has been validated which we can see on the following lines below:
instance.validate(schema);
instance.addDomainEvent({
event: instance.toDto(),
eventName: customerAccountCreatedEvent.eventName,
source: customerAccountCreatedEvent.eventSource,
eventSchema: customerAccountCreatedEvent.eventSchema,
eventVersion: customerAccountCreatedEvent.eventVersion,
});Another piece of the puzzle to highlight is the creation of the child value object for Customer Address when we first create the full Customer Account through a static factory method:
public static createAccount(props: NewCustomerAccountProps): CustomerAccount {
const customerAccountProps: CreateCustomerAccountProps = {
firstName: props.firstName,
surname: props.surname,
subscriptionType: SubscriptionType.Basic,
paymentStatus: PaymentStatus.Valid,
playlists: [],
customerAddress: CustomerAddress.create(props.customerAddress),
};
...
}As you can see from the code above, we always create a new CustomerAddress value object as a child of the overall aggregate (more on this in the next section).
This is exactly the same with ‘Creating a Playlist’ on a customer account that already exists, which happens via the top level aggregate Customer Account (as we always do this to ensure the consistency of the full transaction as we discussed above)
public createPlaylist(playlistName: string): CustomerPlaylist {
const playlistProps: NewCustomerPlaylistProps = { playlistName };
const newPlaylist: CustomerPlaylist =
CustomerPlaylist.createPlaylist(playlistProps);
if (this.props.playlists.length === 2) {
throw new MaxNumberOfPlaylistsError(
'maximum number of playlists reached'
);
}
// create the new playlist
this.props.playlists.push(newPlaylist);
this.setUpdatedDate();
this.validate(schema);
...
}We can see from the code above we created a new CustomerPlaylist domain entity via a static factory method, which is then pushed to an array of CustomerPlaylist objects on the top level CustomerAccount. These will all be changed and persisted as a group of related objects.
Looking at our diagram again, we can see where the business logic should live for each object, as well as the overall Use Case discussed in Part 1:
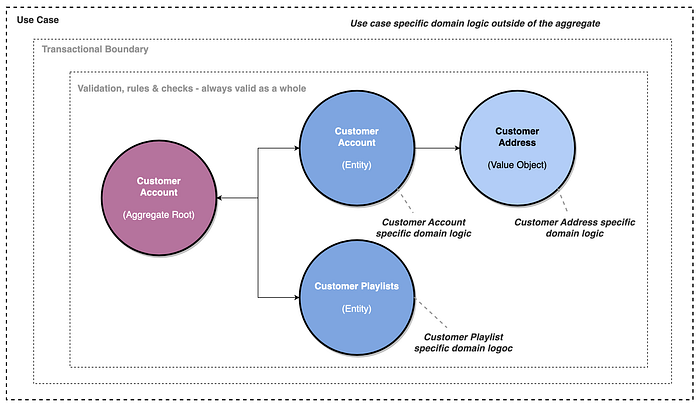
This reduces cognitive load on teams when looking to change or implement new business logic, and it is easier to test.
Aggregate Summary
✔️ Ensures the validity and consistency of a group of related entities and value objects.
✔️ All access to children entities and value objects go via the aggregate root.
✔️ It is the job of the aggregate root entity to publish domain events whenever there is a change within the transactional boundary.
✔️ Ensures that all clustered entities and value objects are changed together for persistence.
Value Objects
We discussed above the notion of a CustomerAddress, and that it is a value object, but what does that actually mean? The definition of a Value Object is:
“There are many objects and data items in a system that do not require an identity and identity tracking, such as value objects. A value object can reference other entities. For example, in an application that generates a route that describes how to get from one point to another, that route would be a value object. It would be a snapshot of points on a specific route, but this suggested route would not have an identity, even though internally it might refer to entities like City, Road, etc” — https://learn.microsoft.com/en-us/dotnet/architecture/microservices/microservice-ddd-cqrs-patterns/implement-value-objects
So in essence, a Value Object (in our case a Customer Address), has no identity unlike its friend the Entity (which always has a unique ID property), and it should be an immutable object which is linked to one or more entities.
Immutability is an important requirement. The values of a value object must be immutable once the object is created. Therefore, when the object is constructed, you must provide the required values, but you must not allow them to change during the object’s lifetime.
Let’s have a look at the base code for our value objects below:
We can see that this is a very basic abstract class, which also has a validate method on it so we can test with a schema at any given time to not only check any related business logic, but the actual properties on the object too.
Now lets look at an implementation of this base class for CustomerAddress:
We can see from the code that we have some very fictitious business logic which is part of this value object, as shown below:
if (!customerAddress.addressLineOne || !customerAddress.postCode) {
throw new CustomerAddressInvalidError(
'address line one and post code are required at a minimum'
);
}
// this is made up business logic for the demo
if (customerAddress.addressLineFive === 'US') {
throw new CustomerAddressNonUSError(
'Unable to create accounts in the US'
);
}This, alongside the validation of the schema, allows us to ensure that this object is valid and complete whenever it is created immutably.
Value Object Summary
✔️ They have no identity, and are compared to other value objects not by reference, but by shape and properties.
✔️ They are immutable i.e. we always create a new version through a factory method on the class (they never get modified, we always create a new version).
✔️ They are valid at all times i.e. we validate them before creating them.
✔️ They are only accessed via the aggregate root entity; in our case which is the CustomerAccount entity.
Domain Events
We touched upon the creation of the domain events in the ‘aggregate’ section above, but how do we use these domain events if they are stored on the root entity?
Let’s look at the code below for our create-customer-account Use Case:

We can see from the code above that on line 33 we publish the domain events from the aggregate which:
- Retrieves the domain events from the top level aggregate (before clearing them down)
- Publishes the domain events via the repository.
I personally feel that it is the responsibility of the domain entities to create, track and manage the domain events within that transactional boundary, but I don’t want to muddy the domain entity itself with repositories or adapters to actually do the publishing (going back to Part 1 about keeping this pure as a domain entity). There would have been no technical reason not to do this in the domain entity itself though if we wanted to.
The repository used in the use case then publishes the events through a secondary adapter which we can see below (agnostic of technology):
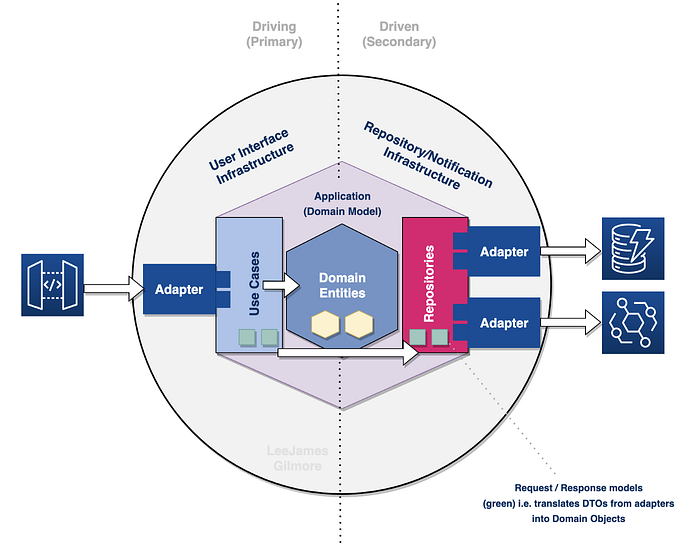
And this repository uses a secondary adapter to perform the actual publishing (meaning we could swap this from EventBridge to any other technology very easily):
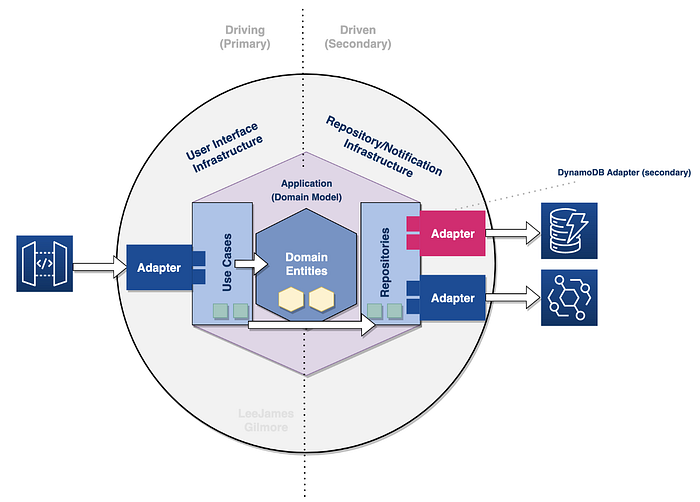
Lee, don’t you usually advise CDC and an Outbox pattern for events?
Yes, when working with Serverless applications I typically use change data capture (CDC) and/or an Outbox pattern to ensure that the domain events are raised. This is discussed in the following article:
We can see a basic example of how this works below:
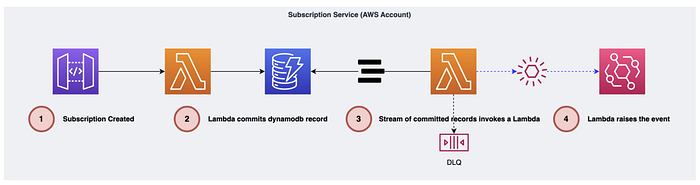
- A user interacts with Amazon API Gateway.
- A Lambda function modifies the record and persists the change to DynamoDB.
- DynamoDB streams is enabled on the database which streams the data changes to a Lambda function.
- The Lambda function reads the stream and publishes the domain events to Amazon EventBridge.
There is no reason why we can’t utilise a similar approach for our example, and in Part 3 we will cover this approach as part of our discussions around CQRS and Event Sourcing.
Do we really need DDD in Serverless?
So, we have discussed over two parts so far the use of domain-driven design in Serverless applications, but is this overkill?
I personally feel that we have the following types of serverless applications which scale from simple and small to complex and enterprise:

As we can see from the basic diagram above we have:
- Small scale applications with little to no business logic which are typically mainly CRUD based. (They may utilise direct integrations, functions, basic workflows etc)
- Enterprise scale applications which are heavy with business logic. (Heavy on rule engines, domain logic, validation, schemas etc — typically based on a digital transformation from a large scale legacy system)
Of course there is nothing stopping us using distributed business logic throughout our enterprise using Lambda functions, Step Functions, direct integrations if the boundaries are correct; however at scale I am always a tad concerned with domain leak, service lock-in (hard to adapt code and services without partial re-writes), and losing sight of where this domain logic lives at scale across many services and domains:
As I often say to teams I work with:
“Be kind to your future selves” — Lee Gilmore
Further information
For a great in depth discussion around Serverless and DDD I would encourage you to view and listen to the following with Jeremy Daly:
https://www.susannekaiser.net/conferences/slides/serverlessdays-belfast-2020.pdf
In summary, the benefits of DDD are widely documented as:
✔️ Prevents domain logic leaking through a service.
✔️ Clear separation between the domain model and the devices/services used for inputs and outputs.
✔️ Prevent technology lock in.
✔️ Allows for non technical use cases which span entities.
✔️ Allows the code to be more easily changed and adapted over time.
✔️ The clear separation allows for easier and more effective testing of our code.
✔️ Allows the domain model to be absent of any technical implementations i.e. focusing purely on the domain and its business logic.
✔️ Conforms to Single Responsibility i.e. SOLID principals.
Summary
I hope you found that useful and interesting when digging deeper into DDD; especially around Aggregates, Value Objects and Domain Events. Join me in Part 3 to discuss CQRS and Event Sourcing with this solution.
Wrapping up 👋
Please go and subscribe on my YouTube channel for similar content!

I would love to connect with you also on any of the following:
https://www.linkedin.com/in/lee-james-gilmore/
https://twitter.com/LeeJamesGilmore
If you enjoyed the posts please follow my profile Lee James Gilmore for further posts/series, and don’t forget to connect and say Hi 👋
Please also use the ‘clap’ feature at the bottom of the post if you enjoyed it! (You can clap more than once!!)
About me
“Hi, I’m Lee, an AWS Community Builder, Blogger, AWS certified cloud architect and Enterprise Serverless Architect based in the UK; currently working for City Electrical Factors (UK) & City Electric Supply (US), having worked primarily in full-stack JavaScript on AWS for the past 6 years.
I consider myself a serverless advocate with a love of all things AWS, innovation, software architecture and technology.”
*** The information provided are my own personal views and I accept no responsibility on the use of the information. ***
You may also be interested in the following:
