
Serverless Threat Modelling 🚀
How and why you should threat model your Serverless solutions on AWS, with visual examples of a real life walk through.
Introduction
The new era of Serverless on AWS, and how quickly we can chain services together into complex architectures to meet customer needs, also has the added downside of increasing the overall threat landscape compared to more traditional architectures.
The new era of Serverless on AWS, and how quickly we can chain services together into complex architectures to meet customer needs, also has the added downside of increasing the overall threat landscape compares to more traditional architectures.
This article will cover why I feel it is imperative for threat modelling to become part of the development lifecycle for Serverless teams, but not necessarily in the historic incarnation of threat modelling that teams may have done in the past; which where seen as more waterfall than agile, and quite frankly long winded and not fun!
We will walk through a fictitious example of a team threat modelling a new HR system which is being built called ‘LeeJames HR’, and see the tangible benefits of the process.
What is threat modelling?
So firstly let’s cover what threat modelling is before we apply it to Serverless.
Threat modelling is defined as:
“Threat modelling is a process by which potential threats, such as structural vulnerabilities or the absence of appropriate safeguards, can be identified, enumerated, and mitigations can be prioritised. The purpose of threat modelling is to provide defenders with a systematic analysis of what controls or defenses need to be included, given the nature of the system, the probable attacker’s profile, the most likely attack vectors, and the assets most desired by an attacker. Threat modelling answers questions like “Where am I most vulnerable to attack?”, “What are the most relevant threats?”, and “What do I need to do to safeguard against these threats?”.” — Wikipedia
“Where am I most vulnerable to attack?”, “What are the most relevant threats?”, and “What do I need to do to safeguard against these threats?”.”
Threat modelling methodologies such as STRIDE and PASTA have historically been used to understand and mitigate potential attacks from bad actors, but this is even more important in the Serverless World where we move away from traditional n-tier applications, to more event driven architectures comprised of many individual AWS services and integration points (which all have their own verbose configurations):

As you can see from the fictitious diagrams above, there are many more data flows, consumers and integration points typically with event driven Serverless architectures on AWS, and each of those services has its own complex configuration to understand, and therefore an increased attack surface to think about.
Let’s look at the STRIDE model 👀
With most of the teams I currently support as a Principal Developer and Cloud Architect, I typically run through the STRIDE model with them when there are:
- New services being architected.
- or, significant changes to actors, existing data flows or architectures currently in place.
The STRIDE model is a way of identifying potential threats of above using the following key areas:
- Spoofing
- Tampering
- Repudiation
- Information disclosure (privacy breach or data leak)
- Denial of service
- Elevation of privilege
Let’s look at each area in more detail 👀
We can use the fantastic resources from ThoughtWorks to get great definitions of each area.
Spoofing (Identity & Authentication)
How hard is it for an attacker to pretend to be someone with authority to use the system? Can someone spoof an identity and then abuse its authority? Spoofing identity allows attackers to do things they are not supposed to do. An example of identity spoofing is an attacker illegally accessing and then using another user’s authentication information, such as username and password.
Tampering (Integrity, Validation, Injection)
How hard is it for an attacker to modify the data they submit to your system? Can they break a trust boundary and modify the code which runs as part of your system? Tampering with input can allow attackers to do things they are not supposed to do. An example of tampering with input is when an attacker submits a SQL injection attack via a web application and uses that action to delete all the data in a database table.
Repudiation (Audit, Signing, Logging & non-repudiation)
How hard is it for users to deny performing an action? What evidence does the system collect to help you to prove otherwise? Non-repudiation refers to the ability of a system to ensure people are accountable for their actions. An example of repudiation of action is where a user has deleted some sensitive information and the system lacks the ability to trace the malicious operations.
Information Disclosure (Leakage, encryption, confidentiality)
Can someone view information they are not supposed to have access to? Information disclosure threats involve the exposure or interception of information to unauthorised individuals. An example of information disclosure is when a user can read a file that they were not granted access to, or the ability of an intruder to read data in transit between two computers.
Denial of Service (Availability, DDoS, CDN & Botnets)
Can someone break a system so valid users are unable to use it? Denial of service attacks work by flooding, wiping or otherwise breaking a particular service or system. An example of denial of service is where a Web server has been made temporarily unavailable or unusable with a flood of traffic generated by a botnet.
Elevation of Privilege (Authorisation, isolation & blast radius)
Can an unprivileged user gain more access to the system than they should have? Elevation of privilege attacks are possible because authorisation boundaries are missing or inadequate. An example of elevation of privilege is where a user can manipulate the URL string to gain access to sensitive records they should not be able to see.
How do we approach threat modelling? 🤔
OK, so we have determined there is a new solution we need to threat model, so let us see how the team approach it with their new design for ‘LeeJames HR’, using the approach I go through with my own teams.

The threat modelling session
Kim books in the meeting for the team for 1 hour, which she is going to facilitate, but knows that in future sessions the team will no doubt get through this in around 30 minutes when the process becomes second nature, and there are smaller changes to threat model!
Remember with Serverless architectures this should be done little and often as changes are introduced — Lee Gilmore
Doug who is the technical architect in the team has put the architecture diagram for ‘LeeJames HR’ onto the screen for the team to look at, which includes actors, data flows, data, assets, AWS services, integration points etc.
The full team is invited, including QA, developers, business analysts, POs.. etc
Ensure that you also have a whiteboard and sticky notes ideally as you will need them when we get going, but of course these can be virtual— Lee Gilmore

As this is the first discussion around the proposed architecture the team are going to look at this broadly, whereas in the future they will be able to threat model regularly and more focused when there are any significant changes to the system (but obviously much smaller).
Evil Brainstorming 😈
The team now walk through the architecture diagram data flows using the STRIDE model and their example definitions (above), and add virtual/or physical sticky notes for each of the potential threats they can think of onto the diagram. There are no wrong answers here — and the team should be able to add anything that comes to mind!
It’s useful to stay focused on realistic threats compared to terrorist attacks globally on all data centres or aliens landing, as there is only so much we can mitigate!— Lee Gilmore
The process should be around 45 minutes — and try to make it fun!
Over time the team will have a mental list in their heads of the potential threats that have been discussed in previous sessions, and this makes the Serverless architectures more resilient by design over time, and the sessions quicker! — Lee Gilmore

What potential threats did the team discuss?
The team started off with the base Serverless architecture diagram that Doug had been working on which we can see below:
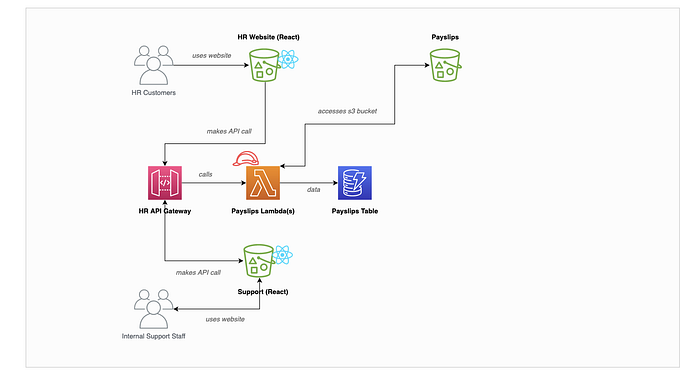
Note — this architecture and product are completely fictitious and for talking through only! Yes things like CloudFront/Route53 etc etc are missing — but lets work on something simple!
Throughout the 45 minute session the team identified a number of threats which were added to the board as sticky notes.
Miro is a great tool for this where the team can collaboratively add virtual sticky notes onto the diagram whilst discussing them, but it can be as simple as a list too — Lee Gilmore
Prioritise the threats!
The team now have the remaining 10–15 minutes to prioritise the threats by voting as a team which have the most risk.
A good way of looking at this is risk X impact i.e. how likely is it that the threat will happen, times by the impact that threat would have on the business; but teams usually have a gut feel on them anyway — Lee Gilmore

These sticky notes can then be added to the backlog in the same order, and the work planned into future sprints!
What threats where identified, and how did this effect the overall future architecture?
Over the coming weeks the team worked through the backlog items which ultimately changed the Serverless architecture of ‘LeeJames HR’ for the better, with each threat and its mitigation discussed below:
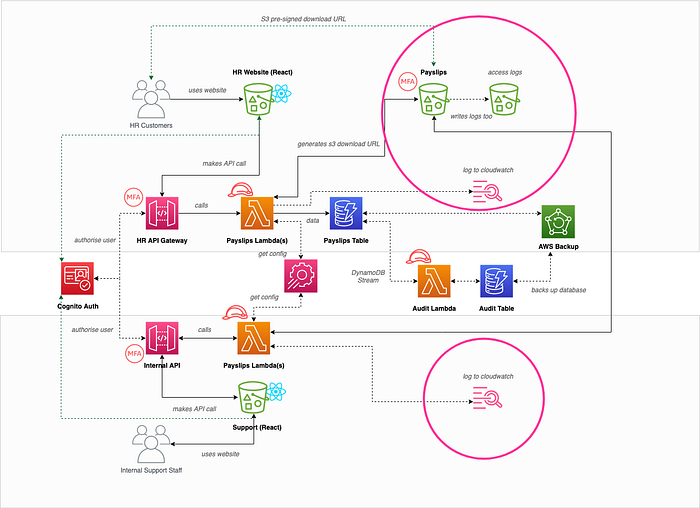
Hand rolled auth over Cognito auth (Information Disclosure and Spoofed Identity)
Sam on the team noticed that we were proposing to create our own authentication processes within the application itself, and as we are not experts in this domain we could end up being easily hacked resulting in information disclosure, or spoofing of identities:
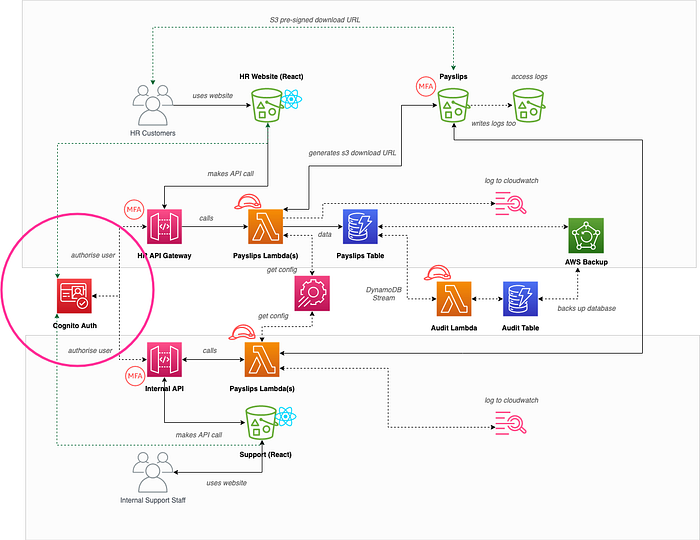
This would be mitigated by introducing Amazon Cognito to authenticate the users along with MFA, and validating the resulting access tokens in API Gateway.
Users and internal staff using the same API (Elevation of Privilege)
Hannah on the team added a ticket that internal support staff and our end users where both using the same API and connected lambdas, and that there was a threat of elevation of privilege if we had any bugs around authorisation.
As you can see from the diagram above it was decided that both types of consumers would have their own dedicated APIs with differing authentication user pools, greatly reducing the chances of cross-contamination.
No auditing of who has done what (Non-repudiation)
Hannah also added a ticket that we had no auditing of changes to data records by our internal staff, and a disgruntled member of staff could be malicious without it ever being tied back to them. For that reason DynamoDB streams was introduced which invoked a lambda in real-time to write audit history to a separate audit table as shown below:
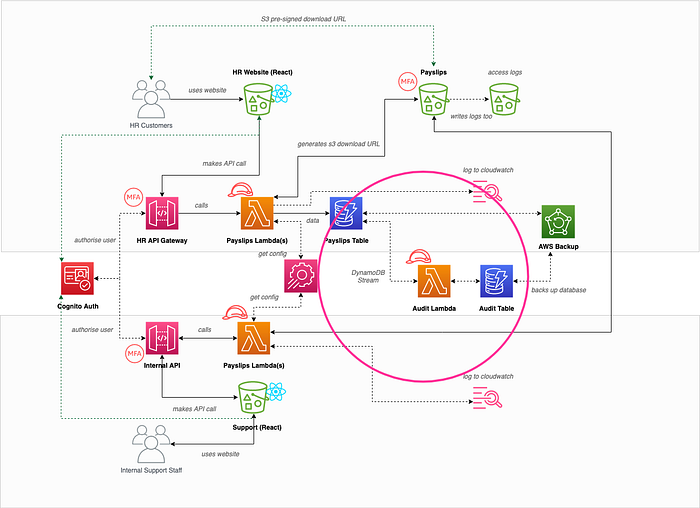
This approach is covered in this blog post
No database backups (Denial of Service)
As they were discussing the lack of auditing from DynamoDB changes, Doug also realised that they were not backing up the databases, and if a bad actor managed to delete the tables or all its items (or a user making a mistake in the console or CLI), then their system would be unusable, and impossible to bring back online! For this reason they introduced regular backups using AWS Backup or PITR in DynamoDB itself.
This is also covered in the link above.
S3 pre-signed download URL (Information disclosure)
The original architecture design had a publicly accessible S3 bucket, and the API returned the file download URL in the API response. Kim realised that bad actors could enumerate the S3 bucket keys to access other peoples payslips!
To fix this, the team added an item on the backlog to make the S3 bucket private, and to return to the user a temporary S3 pre-signed download URL which was specific to them and short lived (as shown in the diagram).
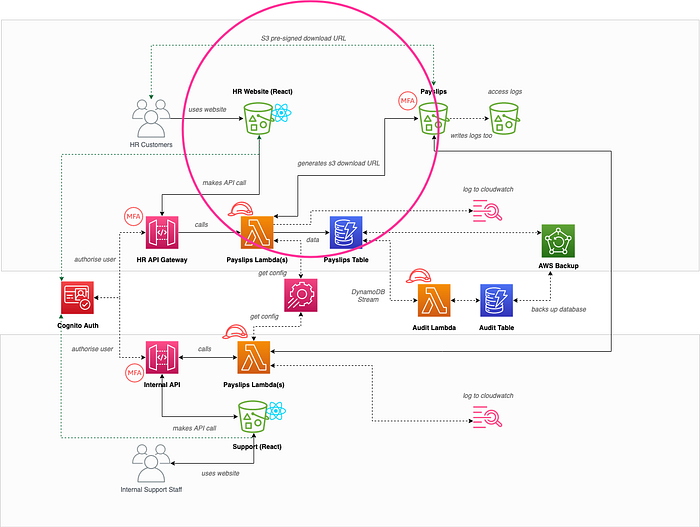
I have wrote a recent blog post that covers this
MFA on S3 bucket for bad actor deleting everything (Denial of Service)
Following discussions around the database, Sam also added a corresponding ticket that a bad actor could potentially delete the S3 bucket contents (that could also have been a member of staff making a mistake), so they decided to add MFA delete to the bucket and versioning (as shown above).
No logging access (lambdas, lambda auth, and s3 access) and Non-repudiation & PII (information disclosure/GDPR)
The team discussed that although they were now auditing changes to the data itself in DynamoDB, they didn’t have any useful logs going to CloudWatch showing what was happening within the system itself, and who was accessing the S3 bucket. For this reason the team added additional logging to CloudWatch, and wrote the S3 access logs to a separate bucket.
There was also a note on the same ticket to ensure that no PII (Personal Identifiable Information) such as names, payslip information, access tokens etc were added to the logs. One, this was more than likely to breach GDPR, but two, it also allowed a bad actor to harvest customer data to be used in a malicious way!
You can also use Amazon Comprehend to remove PII which is discussed in this post:
Config secrets stored in repo (Spoofed identity/information disclosure)
Doug also added a ticket that he noticed all of the config and API keys etc were historically accessible in the code repositories, and that anybody who had access to GitHub could therefore use the config and keys maliciously! Before starting the project it was therefore agreed to use AppConfig, Parameter Store and Lambda Layers to ensure that secrets were stored, encrypted, rotated and accessed correctly.
I wrote a recent blog post which covers this
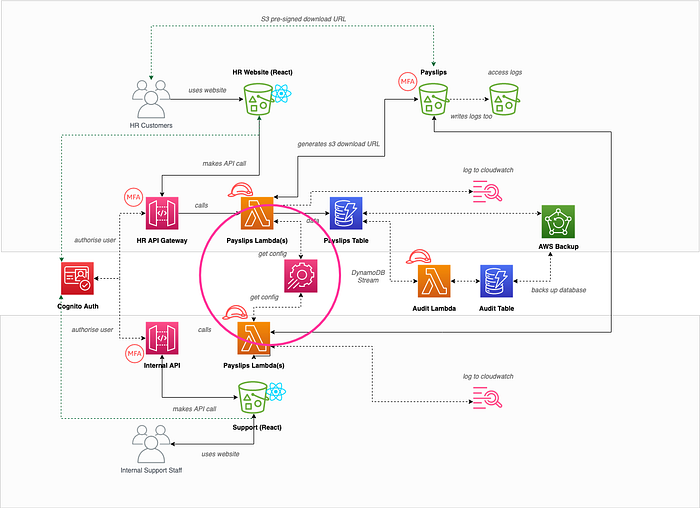
One role for all lambdas (Blast radius/Isolation/least privilege)
Sam had been reading about least privilege in the AWS White Papers, and Doug had documented that all of the lambdas would use the same IAM role for ‘management simplicity’.
Sam explained to Doug that we should add a ticket to ensue that the lambdas (and any other services) each have their own IAM roles that only have the permissions to do explicitly what they need to, therefore reducing the blast radius of somebody comprising that role.
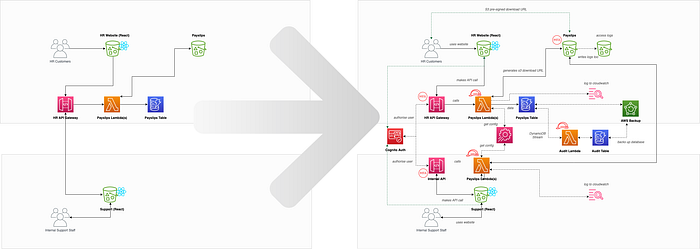
So how do the two architectures compare following threat modelling?
We can see the differences in the diagram below, with the one on the right being much more secure from threats following threat modelling outputs being pulled into sprints.
What can we take from this?
OK, OK… that was a totally fictitious team, proposed architecture and product (and not very well architected in the first place!), but it does give you some insight into how threat modelling should be part of your teams Serverless SDLC, and the tangible benefits that come off the back of it!
A further change to the architecture could result in a quick 15–30 minutes threat model session next time round, and can even be three amigo’d.
How does it work in an Agile World?
The biggest difference to me personally with threat modelling in an agile Serverless World is that I don’t believe you need to create reams and reams of documentation off the back of it. Traditional threat modelling was document and process heavy in my experience, and I like to keep this as lean as possible.
A basic list transferred to a backlog is good enough for me — and means teams don’t see this as an arduous task and boring! It also should be noted that when architected in the first place the Well Architected Framework should be taken into consideration, as well as use of Trusted Advisor.
Over time this becomes second nature, quick, and most importantly fun! Although I have never tried it personally I am sure there would be a way of gamifying this too!
Wrapping up 👋
I hope you found that useful!
Please go and subscribe on my YouTube channel for similar content!
I would love to connect with you also on any of the following:
https://www.linkedin.com/in/lee-james-gilmore/
https://twitter.com/LeeJamesGilmore
If you enjoyed the posts please follow my profile Lee James Gilmore for further posts/series, and don’t forget to connect and say Hi 👋
Please also use the ‘clap’ feature at the bottom of the post if you enjoyed it! (You can clap more than once!!)
This article is sponsored by Sedai.io

About me
“Hi, I’m Lee, an AWS Community Builder, Blogger, AWS certified cloud architect and Principal Software Engineer based in the UK; currently working as a Technical Cloud Architect and Principal Serverless Developer, having worked primarily in full-stack JavaScript on AWS for the past 5 years.
I consider myself a serverless evangelist with a love of all things AWS, innovation, software architecture and technology.”
** The information provided are my own personal views and I accept no responsibility on the use of the information. ***
