
Storage-First Serverless Solutions 🚀
A real World example of using storage-first serverless solutions for increased resilience, with example code using TypeScript and the AWS CDK with both Amazon EventBridge and Step Function Express Workflows.

Introduction
This article covers a storage-first approach to increase resilience and durability in serverless solutions through persisting the requests as soon as viably possible through direct service integrations before performing any business logic, and then subsequently processing them including retry mechanisms for failures. This pattern is very different to the typical approach of processing requests as soon as possible through compute services like AWS Lambda, which we discuss below.

In this example we will be persisting online orders through our fictitious company ‘Lee’s Pizzas 🍕’ in Amazon EventBridge and Step Function Express Workflows state before processing through AWS Lambda, allowing us to store the events for a period of time for increased resilience.
“By default, EventBridge retries sending the event for 24 hours and up to 185 times with an exponential back off and jitter, or randomised delay. If an event isn’t delivered after all retry attempts are exhausted, the event is dropped and EventBridge doesn’t continue to process it. To avoid losing events after they fail to be delivered to a target, you can configure a dead-letter queue (DLQ) and send all failed events to it for processing later.” — https://docs.aws.amazon.com/eventbridge/latest/userguide/eb-rule-dlq.html
“The new AWS Step Functions Express Workflows type uses fast, in-memory processing for high-event-rate workloads of up to 100,000 state transitions per second, for a total workflow duration of up to 5 minutes” — https://aws.amazon.com/blogs/compute/new-express-workflows-for-aws-step-functions/
You can access the code repo here, but please note this is not production ready code and is to illustrate the approach only:
https://github.com/leegilmorecode/serverless-storage-first
👇 Before we go any further — please connect with me on LinkedIn for future blog posts and Serverless news https://www.linkedin.com/in/lee-james-gilmore/

What are we building? 🏗️
For our fictitious online pizza company we are going to create an Amazon API Gateway with three endpoints, one for placing a new order, one for cancelling an order, and one for listing all orders (as shown below)

As you can see from the diagram above we cover:
- Creating a pizza order which goes directly from Amazon API Gateway to Amazon EventBridge for resilience using a direct integration i.e. we won’t lose the request as it is instantly persisted, before a consuming Lambda processes it asynchronously as a target. If there are issues processing the order then it will go to an SQS dead letter queue to be processed later.
- Canceling an order which utilises an Express Workflow Step Function in the same vain i.e. we won’t lose the request as it is persisted in state using a direct integration, before processing the cancellation synchronously. This allows us to use a retry mechanism for up to 5 minutes if needed, but we simply send to a DLQ if it throws an error for the simple example.
- Finally a list orders endpoint which is a more traditional method of using Lambda to retrieve the orders via RDS Proxy so we can see this working.
💡 Note: Synchronous Express Workflows guarantee at-most-once workflow execution.
What is storage-first as an approach?
When we build our traditional services in Serverless we typically go for the following approach of API Gateway/AppSync, Lambda and a database (for example Aurora or DynamoDB):

This is a very valid and common approach, but if the Lambda fails to process the request for any reason then the request can be lost (unless it is persisted on failure), and the consumer gets a 4XX error. The consumer would then need to retry the API request again which can be frustrating!
“In our example scenario we want to ensure that the online order is always processed or cancelled, so we aim to persist the request as soon as possible.”
An alternative approach for certain use cases is to persist the request message as soon as possible and return a 200 status code back to the consumer. This way, if we fail to process the message correctly then it is not lost i.e. it is persisted first, and we can replay it or try again to our hearts content:
Synchronous Express Workflows start a workflow, wait until it completes, then return the result. Synchronous Express Workflows can be used to orchestrate microservices, and allow you to develop applications without the need to develop additional code to handle errors, retries, or execute parallel tasks. Synchronous Express Workflows can be invoked from Amazon API Gateway, Amazon Lambda, or by using the
StartSyncExecutionAPI call.

“Using the storage first pattern with direct integrations can help developers build serverless applications that are more durable with fewer lines of code. A Lambda function is no longer required to transport data from the API endpoint to the desired service. Instead, use Lambda function invocations for differentiating business logic.” — Eric Johnson, AWS Principal Developer Advocate
We can use a number of AWS services to persist our requests off the back of API Gateway:
✔️ Amazon SQS
✔️ Amazon Step Functions
✔️ Amazon EventBridge
✔️ Amazon Kinesis Data Streams
Let’s cover some of them below in the next section.
What services are we using? 🧰
✔️ EventBridge
Amazon EventBridge is a serverless event bus that makes it easier to build event-driven applications at scale using events generated from your applications, integrated Software-as-a-Service (SaaS) applications, and AWS services. EventBridge delivers a stream of real-time data from event sources such as Zendesk or Shopify to targets like AWS Lambda and other SaaS applications.
✔️ StepFunctions
AWS Step Functions is a low-code, visual workflow service that developers use to build distributed applications, automate IT and business processes, and build data and machine learning pipelines using AWS services. Workflows manage failures, retries, parallelization, service integrations, and observability so developers can focus on higher-value business logic.
✔️ Serverless Aurora V2
Aurora Serverless v2 is an on-demand, autoscaling configuration for Amazon Aurora. Aurora Serverless v2 helps to automate the processes of monitoring the workload and adjusting the capacity for your databases. Capacity is adjusted automatically based on application demand. You’re charged only for the resources that your DB clusters consume. Thus, Aurora Serverless v2 can help you to stay within budget and avoid paying for computer resources that you don’t use.
Deploying the solution 🏗️
⚠️ Note: You will be charged for deploying this solution.
We can deploy the solution by performing the following steps in the infra folder and then the orders-service folder:
npm run deployWe can remove the solution by performing the following steps in the orders-service folder and then the infra folder:
npm run removeTesting the solution 🎯
You can use the Postman file which is located here ./postman/Serverless Storage First.postman_collection.json to test out how the solution works:

💡 Note: for ease of the demo our database table ‘online’ only has one column called ‘username’ as opposed to a fully fledged order i.e. what the customer wants to order and their address etc
Talking through key code 💬
So, now that we have talked through the services used, deployed the solution and tested it; let’s now talk through some of the key code:
Serverless Aurora V2
As there are no supporting constructs for the CDK as of yet for Serverless Aurora V2 we have needed to perform some work arounds as shown below:
Amazon RDS Proxy
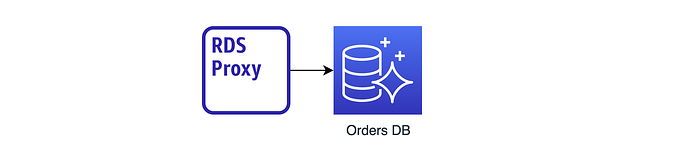
Now that we have our Amazon Serverless Aurora V2 (Postgres) database available to us, we utilise RDS Proxy to sit in between our Lambdas and database as a connection management proxy for our ephemeral services i.e. Lambda:
Custom Resource
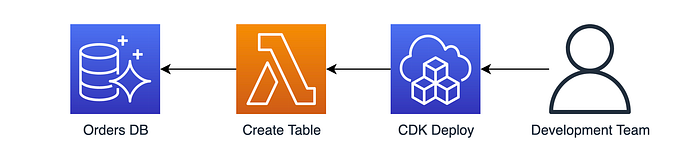
We now have our database and proxy setup, but we need a way of provisioning the Postgres database table as part of our CDK deployments… this is where Custom Resources come in!
For more information on Serverless Custom Resources you can see a previous article below.
You can see from the code below that we use a custom resource to invoke a Lambda through the underlying CloudFormation on create, update or delete of the stack:
This then invokes the following Lambda which provisions the Postgres ‘online’ database table on create or update of the stack:
Now we have the database, the proxy and the Postgres table setup to play with, now let’s move onto the storage-first parts.
Express Workflow State Machine Integration
We use the following code for allowing us to hook up our API Gateway cancel order endpoint with our Express Workflow so it is invoked synchronously using a direct integration, which is storage-first as the state is persisted for the duration of the execution:
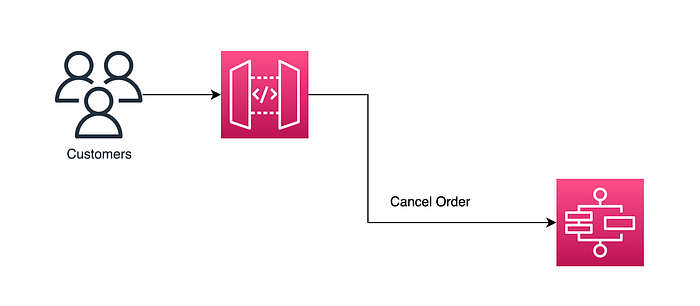
This means that within the 29 seconds we have for the Express Workflow to return a response to API Gateway we can design a workflow that allows for multiple retries on error with exponential backoff etc, ultimately allowing us to persist in an SQS dead-letter queue on total failure allowing us to replay the message later.
The workflow is shown below:
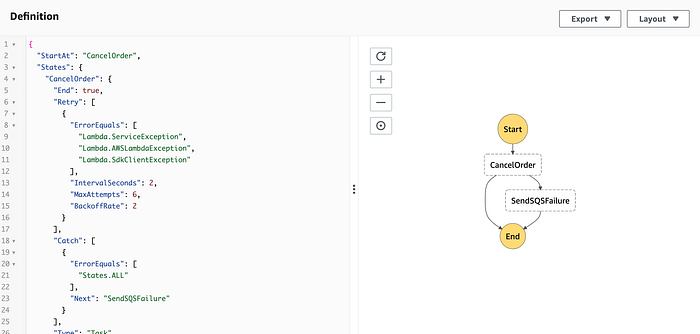
As you can see it is very, very basic. It invokes the Lambda within the workflow to cancel an order and then puts the message onto an SQS dead-letter queue if there are any errors. We could of course add some detailed workflow logic in here which retries based on the database being unavailable etc for example.
This is generated through the following code:
You can see from the code example that we need to create a role that allows API Gateway to invoke the workflow with a startSyncExecution action. We then create an integration option which returns to the user a 200 response code from the workflow with a message of ‘Cancelled’, regardless of it being successful or not (as we would deal with any total failures for the customers if and when they happen).
Amazon EventBridge Integration
As we have already setup our API Gateway IAM role above, now we just need to integrate Amazon EventBridge with our API:
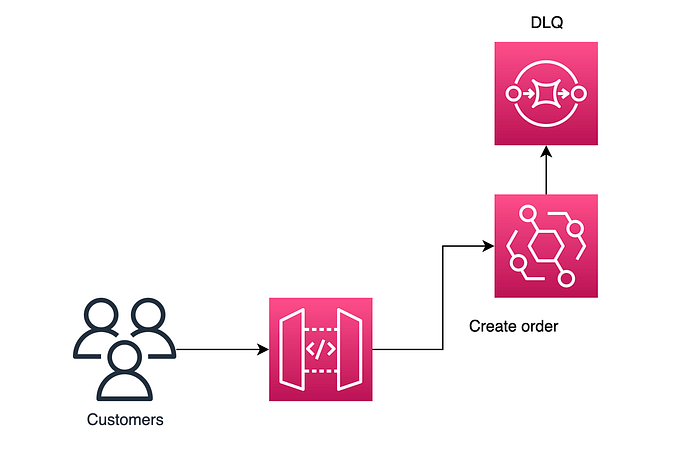
We can see that similar to the Step Function integration we simply return a 200 with ‘Created’ back to the customer and persist the request onto an Event Bus. This is subsequently processed using a create-order Lambda through a Target Rule, and subsequently if there are any errors it is persisted to a dead letter queue with SQS.
This is a storage-first pattern as the message will be persisted to the event bus using a direct integration, and if there are any issues in routing to the Lambda as a target it will retry for up to 24 hours.
The Lambda uses Destinations to persist the request to the dead-letter queue on error using the following code in the CDK definition of the Lambda:
onFailure: new destinations.SqsDestination(createOrderLambdaDlq),For more information about Lambda Destinations you can see this previous article:
Summary
I hope you found that useful as a very basic example of using two AWS Services along with storage-first as a design pattern.
Wrapping up 👋
Please go and subscribe on my YouTube channel for similar content!

I would love to connect with you also on any of the following:
https://www.linkedin.com/in/lee-james-gilmore/
https://twitter.com/LeeJamesGilmore
If you enjoyed the posts please follow my profile Lee James Gilmore for further posts/series, and don’t forget to connect and say Hi 👋
Please also use the ‘clap’ feature at the bottom of the post if you enjoyed it! (You can clap more than once!!)
About me
“Hi, I’m Lee, an AWS Community Builder, Blogger, AWS certified cloud architect and Enterprise Serverless Architect based in the UK; currently working for City Electrical Factors (UK) & City Electric Supply (US), having worked primarily in full-stack JavaScript on AWS for the past 6 years.
I consider myself a serverless advocate with a love of all things AWS, innovation, software architecture and technology.”
*** The information provided are my own personal views and I accept no responsibility on the use of the information. ***
You may also be interested in the following:
